Two thousand years ago the Romans had the word probabilis. If something was probabilis then it could be proved by experiment, because the two words come from the same root: probare. But probabilis got overused. People are always more certain of things than they really should be, and that applied to the Romans just as much as to us. Roman lawyers would claim that their case was probabilis, when it wasn’t. […] So by the time poor probably first turned up in English in 1387 it was already a poor, exhausted word whose best days were behind it, and only meant likely.
— Mark Forsyth, The Etymologicon
1/ Regressão Linear
Várias abordagens mais avançadas de aprendizado estatístico são generalizações da Regressão Linear. É relevante construir uma base sólida sobre seu funcionamento. Como visto no capítulo anterior, ela é uma função do primeiro grau com coeficientes e , respectivamente a interseção e a inclinação da reta.
A estimativa dos coeficientes é determinante para prever valores futuros e identificar o quão forte as variáveis estão relacionadas. A diferença entre a estimativa e o valor real representa o residual
Vamos supor que seja a venda e corresponda ao investimento em propaganda de produtos ( é celular e é computador). Iremos organizar os dados observados em pares de valores , , …, . Na observação , um investimento de R$2000,00 resultou na venda de 12 unidades de celular. De maneira intuitiva, a melhor reta é aquela que atravessa o gráfico minimizando a distância entre a reta e os pontos circundantes. Idealmente a diferença é zero, mas isso nunca acontece em observações reais.
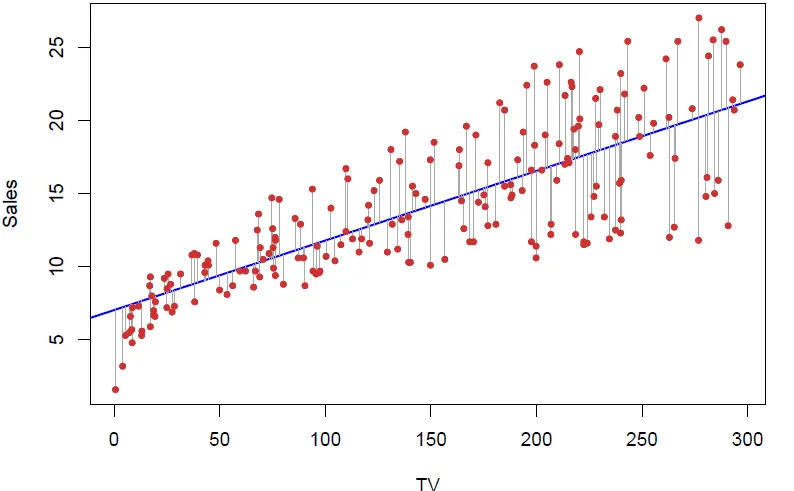
Minimizar os residuais é encontrar a melhor estimativa possível dos coeficientes, e com isso boas aproximações para o valor real. A função de custo (cost function, ou também loss function) tem o propósito de medir a proximidade. Uma das maneiras mais populares é via RSS (Residual Sum of Squares):
RSS traz as seguintes vantagens:
- Garante que o resultado seja sempre positivo
- Dá maior peso para os pontos mais afastados da reta
- Ao contrário do valor absoluto, é diferenciável em todo seu domínio, inclusive na origem. Muito útil para o Grandiente Descendente e outras técnicas futuras
O último motivo para usar quadrados está ligado ao ruído gaussiano (gaussian noise). Isso está melhor explicado no primeiro link em Recursos Adicionais, mas o que acontece é o seguinte: em todo sistema complexo haverá causas independentes para o erro entre o modelo e a realidade. De acordo com o Teorema do Limite Central, o ruído total segue a forma de uma distribuição normal (gaussiana). Sabemos que a distribuição normal tem dois parâmetros, a média e a variância.
Um dos termos da variância é numericamente idêntico ao RSS. Assim, minimizar o RSS é o mesmo que reduzir o erro randômico do sistema, a variância. Em essência, estamos lidando com uma distribuição gaussiana. Observe que cada função de custo corresponde a alguma distribuição de ruído.