There’s obviously a hierarchy of information. It ranges from life-changing good to life-changing disastrous. That got me thinking: What would be the most interesting and useful information anyone could get their hands on?
— Morgan Housel, CollabFund
Na análise de dados, o que desejamos fazer é realizar previsões, avaliar a qualidade das previsões e entender o comportamento dos fenômenos observados. De modo geral, essa é a ordem de importância para o mercado. Tópicos abordados:
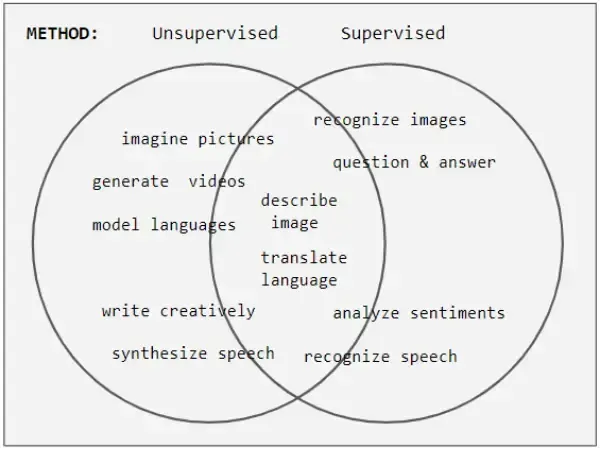
- aprendizado supervisionado e não-supervisionado
- regressão e classificação
1/ Introdução
Todo modelo matemático terá variáveis de entrada e de saída, que correspondem a X e Y. Podemos chamar Y de variável dependente, aquilo que se deseja prever.
X é a variável independente, um vetor composto por p preditores para encontrar a melhor estimativa para Y. Nota-se na equação acima um epsilon: este é o erro inerente a qualquer modelo, o qual não pode ser reduzido. Há sempre um limite para quantas variáveis se observa, a qualidade dessa observação e o limite do próprio modelo em fazer a predição. Afinal, o mapa não é o território.
Problemas de classificação são uma classe de problemas que tentam prever a qual grupo Y pertence entre um número finito de alternativas. Por exemplo, prever se uma instância de Paciente deveria ser colocada no grupo “urgência”, “emergência” ou “consulta” com base em suas características.
Já os Problemas de Regressão preveem um valor numérico. Mas isso nem sempre é tão bem definido assim; a Regressão Logística pode ser usada tanto para previões quantitativas quanto para as qualitativas, uma vez que fornece probabilidades para cada grupo.
No Aprendizado Não-Supervisionado existem os preditores X, mas não existe um Y definido. O objetivo é fuzzy, “bagunçado”, tenta-se encontrar possíveis relações entre os tipos. É difícil averiguar a qualidade por não ter um objetivo. Bom para pré-processamento.
2/ Qualidade do Encaixe
Em Regressão, a medida da qualidade da previsão mais comum é o MSE (mean squared error), o erro médio quadrático.
Treina-se ele a partir dos dados de treinamento, e depois testamos nos dados de teste (nunca antes vistos pelo modelo). Na prática, não importa muito o desempenho nos dados de treinamento, e sim no de teste.
Na imagem abaixo há dois gráficos: o gráfico da esquerda exibe uma série de pontos do conjunto de treinamento e uma curva preta que representa a função verdadeira; as curvas de outras cores são curvas com diferentes graus de liberdade (flexibility) estimadas a partir do treinamento.
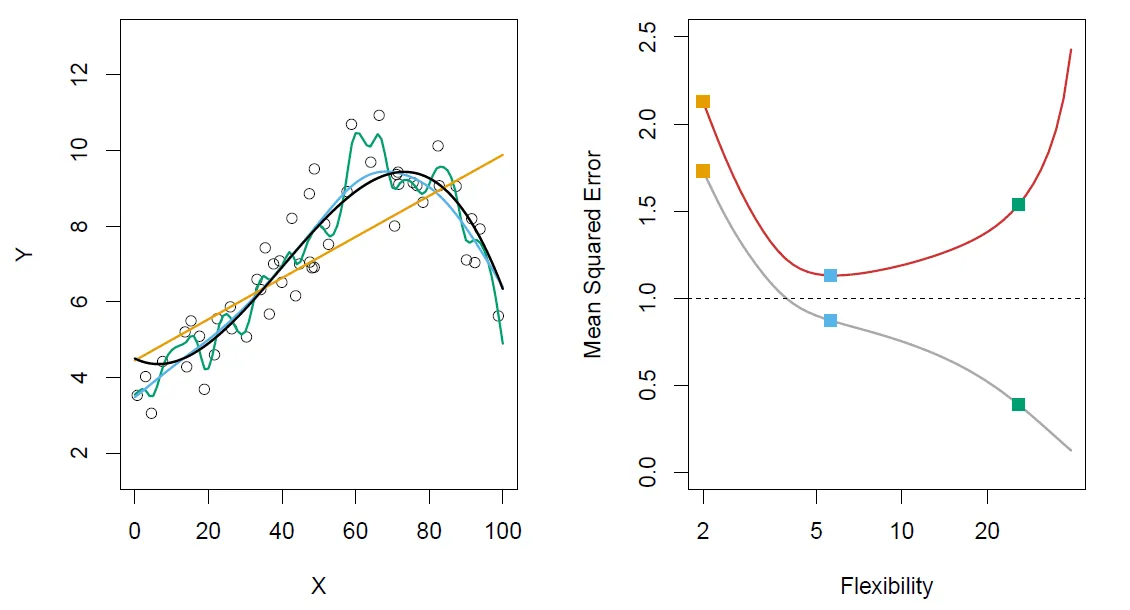
No gráfico da direita a curva vermelha representa o resultado do MSE de teste. A cinza do MSE de treinamento. Já a linha tracejada demarca a variância, ou seja, o erro irredutível do sistema.
[…] we observe a monotone decrease in the training MSE and a U-shape in the test MSE. This is a fundamental property of statistical learning that holds regardless of the particular data set at hand and regardless of the statistical method being used. As model flexibility increases, the training MSE will decrease, but the test MSE may not. When a given method yields a small training MSE but a large test MSE, we are said to be overfitting the data.
3/ Tradeoff Viés-Variância
Though the mathematical proof is beyond the scope of this book, it is possible to show that the expected test MSE, for a given value x0, can always be decomposed into the sum of three fundamental quantities: the variance of , the squared bias of and the variance of the error variance terms .